Background Jobs
On this page
Not everything should happen during a request. Sending emails, generating reports, processing images, syncing data, these are slow operations that shouldn’t make your user wait.
The solution: push the work to a queue and process it in the background.
The Problem
User signs up: your API needs to:
- Create the user in the database (fast, ~10ms)
- Send a welcome email (slow, ~2 seconds)
- Resize their avatar (slow, ~3 seconds)
- Sync to analytics (slow, ~1 second)
If you do all of this in the request, the user waits 6+ seconds for a signup response. Terrible experience.
The Solution: Message Queues
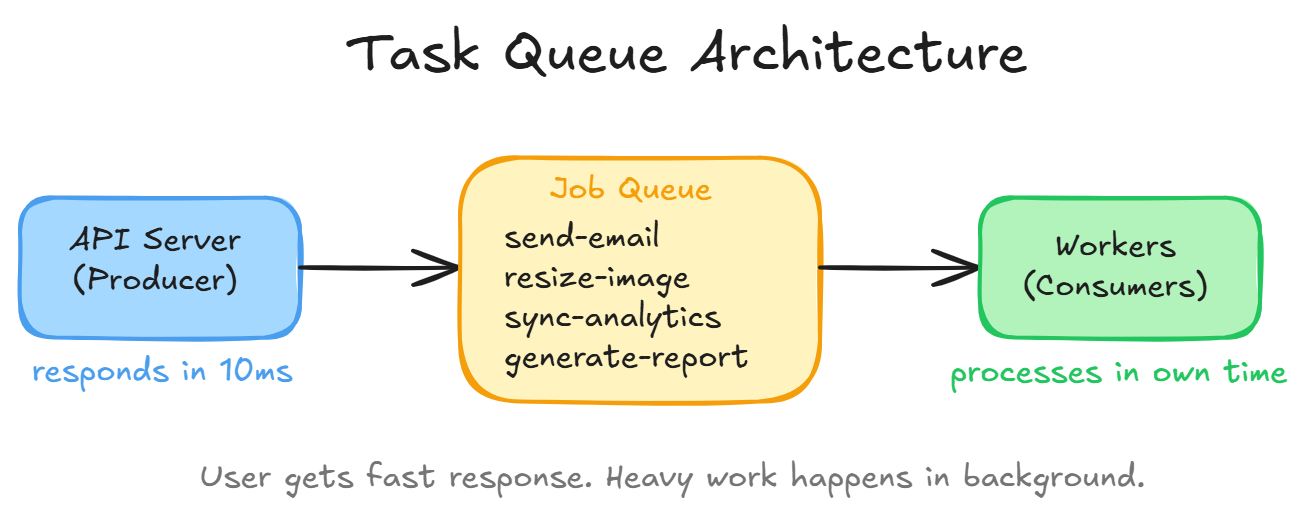
Instead of doing everything synchronously:
- Create the user (fast)
- Push a message to the queue: “send welcome email to user 42”
- Push another message: “resize avatar for user 42”
- Return 201 Created immediately (~10ms response!)
A separate worker process picks up messages from the queue and processes them in the background. The user doesn’t wait.
How It Works
Producer, your API server. It puts jobs on the queue. Queue, a list of jobs waiting to be processed (Redis, RabbitMQ, SQS). Consumer/Worker, a separate process that pulls jobs and executes them.
The queue acts as a buffer. If 1000 emails need sending, they line up. Workers process them at their own pace without overwhelming the email service.
Why Not Just Use setTimeout?
In-process timers die when your server restarts. If your server crashes mid-queue, all pending jobs vanish.
A proper queue (Redis + BullMQ, Celery, Sidekiq):
- Persists jobs to disk
- Retries failed jobs automatically
- Supports delayed/scheduled jobs
- Provides visibility (how many jobs pending, failed, completed)
- Scales by adding more workers
Common Use Cases
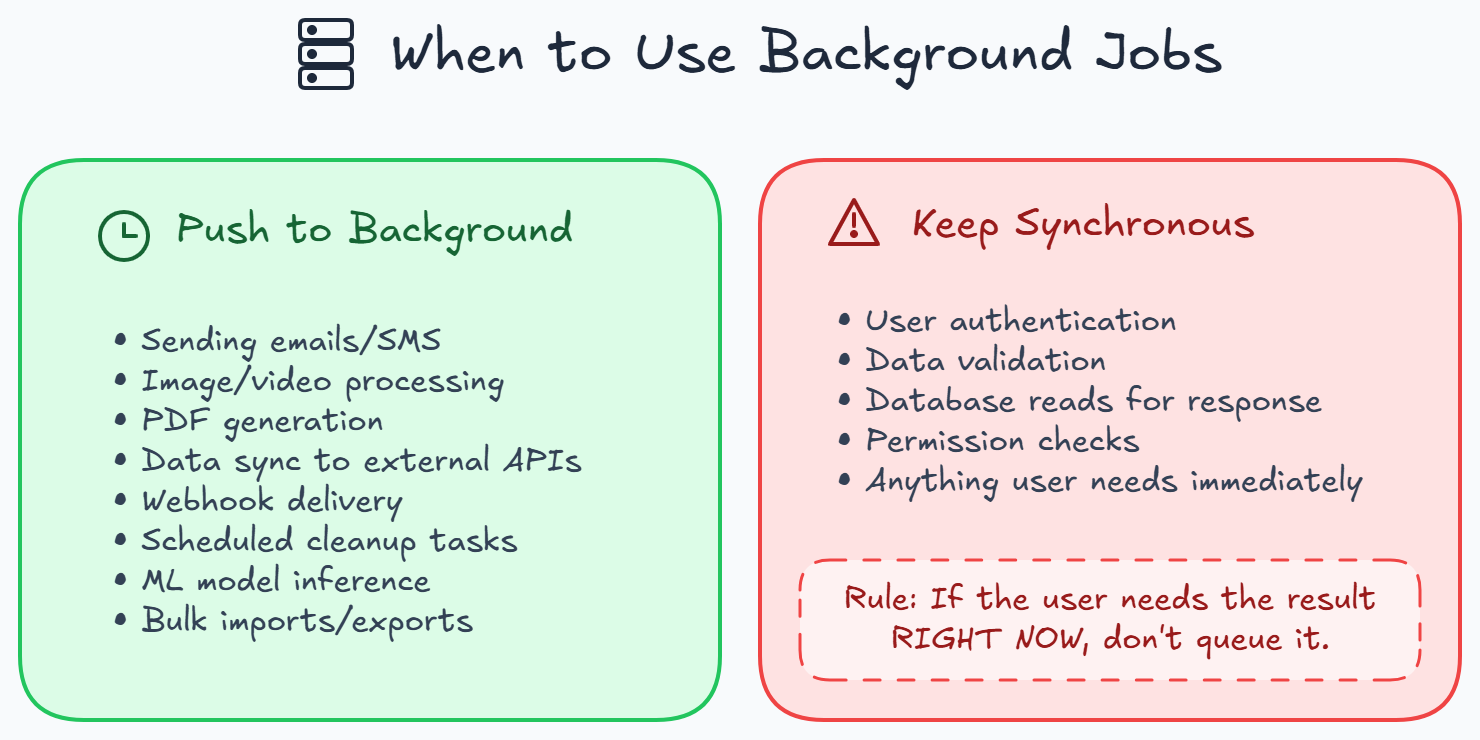
- Sending emails and notifications
- Image/video processing and resizing
- Generating PDFs or reports
- Syncing data to external services
- Scheduled tasks (daily cleanup, weekly reports)
- Webhooks (delivering events to other systems)
- Heavy computations (ML inference, data aggregation)
Retry Strategies
Jobs fail. The email service is down. The API you’re calling returns a 500. Good queue systems handle this:
- Immediate retry, try again right away (maybe it was a blip)
- Exponential backoff, wait 1s, then 4s, then 16s, then 64s
- Dead letter queue, after X retries, move the job to a “failed” queue for manual inspection
- Max retries, give up after N attempts
Wrapping Up
- Background jobs let you respond fast and process slow work later
- Queues decouple producers from consumers
- Workers process at their own pace
- Always handle failures with retries and dead letter queues
- Use established tools (BullMQ, Celery, Sidekiq) not DIY solutions
Day 12 of 95 | Backend Engineering Series