Caching
On this page
Your database query takes 50ms. Your API takes 80ms to respond. That seems fast until you realize that same query runs 10,000 times a minute for the same data that changes once an hour. That’s 10,000 identical database hits for no reason.
Caching means: store the result of expensive operations and reuse it instead of recomputing every time.
The Concept
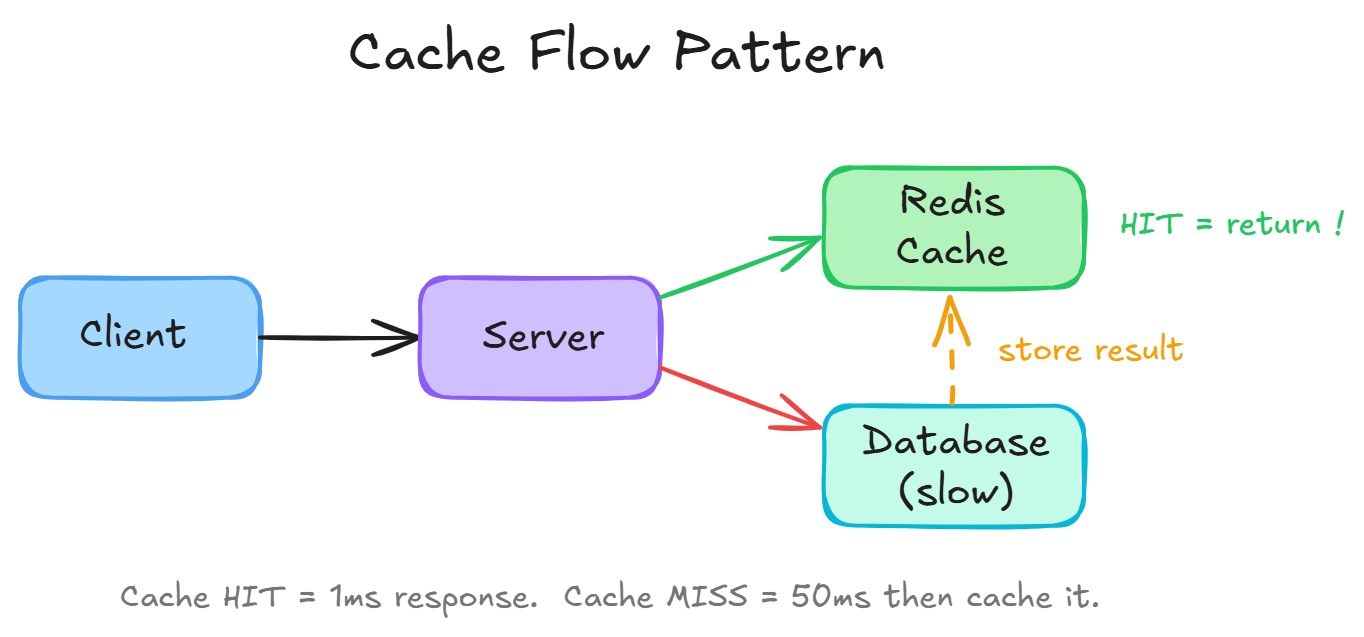
Without cache:
Request → Server → Database: 50ms → Response
Request → Server → Database: 50ms → Response (same data!)
Request → Server → Database: 50ms → Response (still same!)With cache:
Request → Server → Database: 50ms → Store in cache → Response
Request → Server → Cache hit!: 1ms → Response
Request → Server → Cache hit!: 1ms → ResponseOne database hit instead of thousands. That’s the power of caching.
Where to Cache
1. Application-level (in-memory)
- Stored in your server’s RAM
- Fastest possible (no network hop)
- Lost when server restarts
- Not shared between multiple server instances
- Good for: config values, feature flags, small lookup tables
2. Distributed cache (Redis/Memcached)
- Separate server dedicated to caching
- Shared between all your app servers
- Survives app restarts (but not Redis restart)
- Sub-millisecond responses
- Good for: session data, frequently accessed queries, rate limiting counters
3. HTTP caching (CDN/browser)
- Response headers tell the client to cache
- No request even reaches your server
- Good for: static assets, public API responses that rarely change
Cache Invalidation, The Hard Part
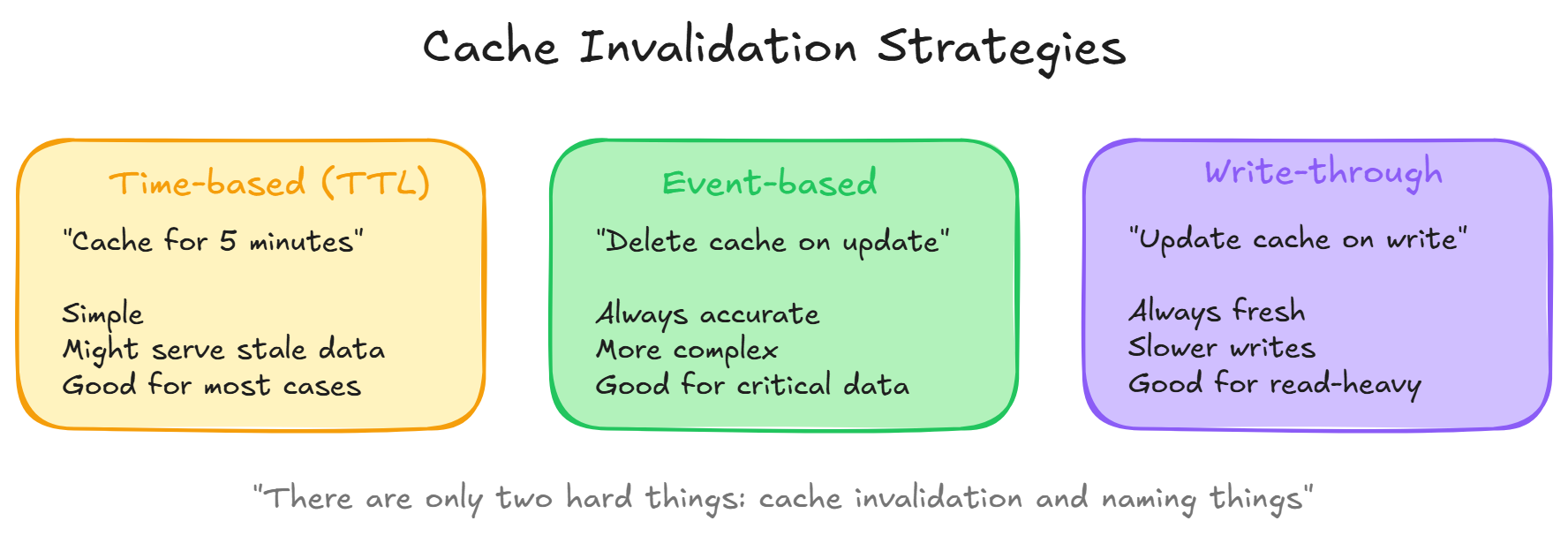
Caching is easy. Knowing WHEN to clear the cache is hard. If your data changes but the cache still serves old data, users see stale information.
Time-based (TTL)
- Set an expiration time: “cache this for 5 minutes”
- After 5 minutes, the next request hits the database again
- Simple but you might serve stale data within the TTL window
Event-based
- When data changes, actively delete the cache entry
- User updates their profile: clear the profile cache
- More complex but always accurate
Write-through
- On every write, update both the database AND the cache
- Cache is always fresh
- Slightly slower writes, always fresh reads
What to Cache (and What NOT To)
Good candidates:
- Data that’s read way more than it’s written
- Expensive queries (JOINs across multiple tables)
- External API responses (weather data, exchange rates)
- Computed results (leaderboards, analytics)
Bad candidates:
- Data that changes every request (real-time stock prices)
- User-specific data that varies per request
- Data where staleness is unacceptable (bank balances)
Redis, The Caching Swiss Army Knife
Redis isn’t just a key-value cache. It supports:
- Strings (simple cache)
- Lists (queues, recent items)
- Sets (unique collections, tags)
- Sorted sets (leaderboards, rankings)
- Hashes (object-like storage)
- TTL on any key (auto-expiration)
Most backends use Redis for caching because it’s battle-tested, fast (100K+ ops/second), and versatile.
Wrapping Up
- Cache expensive, repetitive operations
- Choose the right cache layer (in-memory, Redis, CDN)
- TTL is the simplest invalidation strategy
- Event-based invalidation gives fresher data
- Don’t cache everything, only what’s read-heavy and change-infrequent
- Redis is the industry standard for backend caching
Day 11 of 95 | Backend Engineering Series